在人工智能(AI)迅猛發展的時代,一個新興職業正悄然崛起,成為連接冰冷算法與溫暖人類世界的橋梁——他們就是人工智能訓練師。他們的核心工作,正是用海量數據‘喂養’AI模型,通過精心的‘教導’,讓機器學會理解、模擬并服務于人類。而在這個過程中,公開、多元、高質量的公共數據扮演著至關重要的角色,是訓練出更‘人性化’、更‘懂你’的AI的關鍵養分。
一、 人工智能訓練師:AI的‘人類導師’
人工智能訓練師并非簡單地投喂數據,他們是一群集數據標注、模型調優、效果評估于一身的復合型人才。其工作流程可以概括為:
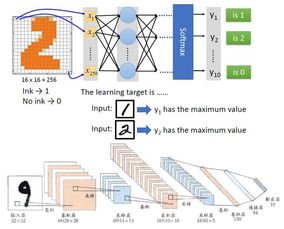
- 數據準備與標注:這是訓練的基礎。訓練師需要根據AI要完成的任務(如圖像識別、語音交互、文本理解),收集并處理大量原始數據。例如,為了讓AI識別貓,他們需要準備成千上萬張包含貓的圖片,并手動或利用工具精確標注出圖片中‘貓’的位置和類別。這個步驟決定了AI學習的‘教材’質量。
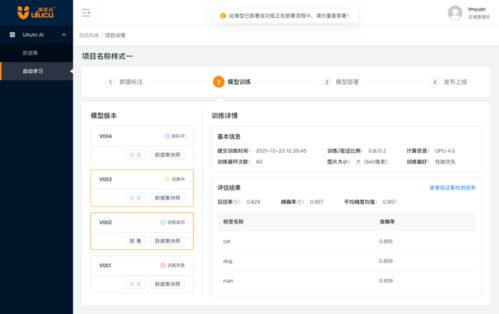
- 模型訓練與調參:將標注好的數據‘喂’給機器學習模型。訓練師需要選擇合適的算法,設置學習率、迭代次數等參數,并監控訓練過程,防止模型‘學偏’(過擬合)或‘沒學會’(欠擬合)。
- 測試與優化:用未參與訓練的新數據測試AI的表現,評估其準確率、響應速度等指標。根據測試結果,訓練師需要分析錯誤案例,返回調整數據或模型參數,進行迭代優化,直到AI達到預期的智能水平。
他們的目標,是讓AI的‘思考’和‘反應’盡可能貼近人類的邏輯與需求。
二、 公共數據:不可或缺的‘營養基’
如果說算法是AI的大腦結構,那么數據就是塑造其思維和認知的‘食物’。而人工智能公共數據——即由政府、科研機構、企業等公開釋放的,可供合法獲取和使用的數據資源——對于訓練出公平、普惠、強大的AI至關重要。
- 規模與多樣性:單個組織擁有的數據往往是片面和有限的。公共數據集合了來自社會方方面面的信息,涵蓋了更廣泛的人群、地域、場景和文化。用這樣的數據訓練AI,能有效避免模型產生偏見(例如,只認識特定膚色的人臉),使其具備更強的泛化能力和包容性,真正‘更懂’全體人類。
- 降低創新門檻:高質量的標注公共數據集(如ImageNet用于計算機視覺,Common Crawl用于自然語言處理)為高校、初創公司乃至個人開發者提供了寶貴的研發資源。這極大地降低了AI研發的成本和門檻,推動了整個生態的創新與繁榮。
- 促進公平與透明:在公共監督下采集和開放的基準數據集,可以作為衡量不同AI模型性能的‘標尺’,促進技術發展的公平競賽。基于公共數據訓練的模型,其決策邏輯也更有機會被檢驗和解釋,有助于增加AI的透明度和可信度。
三、 挑戰與未來:邁向更智慧的‘共育’
盡管前景廣闊,但用數據‘喂養’AI的道路仍面臨挑戰:
- 數據質量與偏見:公共數據本身可能包含社會既有偏見或不準確信息,需訓練師具備高度的倫理意識進行清洗和校正。
- 隱私與安全:在利用公共數據時,必須嚴格遵守法律法規,做好脫敏處理,保護個人隱私和數據安全。
- 場景化與專業化:通用數據難以滿足醫療、法律、工業等垂直領域的深度需求,需要更多高質量、精細標注的行業公共數據出現。
人工智能訓練師的角色將更加重要且復雜。他們不僅是技術專家,還需是倫理學家、社會觀察家。而構建一個更加開放、協作、規范的公共數據生態,鼓勵政府、企業、研究機構共享更多脫敏后的高質量數據,將是培養出真正理解人類、服務人類、與人類和諧共處的下一代AI的必由之路。通過人類訓練師的智慧與公共數據的滋養,我們正在共同‘培育’一個更智能、更友好的數字未來。